Engineering essay · 8 min read
Prompt → Context → Harness
Why building with LLMs feels less like prompt writing and more like software engineering, every year.
TL;DR
- Prompt is the string the model reads in one call.
- Context is everything in the model’s window. Prompt plus retrieved docs, history, tool results.
- Harness is the runtime around the call. Agent loop, tools, hooks, sandbox.
- Each layer wraps the one below. Writing the prompt is roughly 20% of the work. The rest is software engineering.
Side-by-side
Same task, sliced by which layer owns it. The rest of the essay fills this in.
Prompt
- Unit: one model call
- Lever:
prompt | model - Fails as: bad single output, format collapse, refusal
- Mental model: writing instructions
Context
- Unit: the token window
- Lever:
retriever.invoke(),summarize() - Fails as: wrong or stale info, lost-in-the-middle
- Mental model: filling a backpack
Harness
- Unit: the full session
- Lever:
while turn < max_turns: - Fails as: loops, runaway cost, sandbox escape
- Mental model: operating a kitchen
In 2023, “prompt engineer” was a job title. Anthropic posted a listing in the $175K to $335K range, others followed at similar levels. Twitter filled with collections of golden prompts. Courses appeared promising the secret incantations. For a moment it looked like talking to a model was its own discipline, separate from software engineering, accessible to anyone who could write English well. The hype was real, and a lot of it was earned. The first time you saw a clever system prompt make a model behave the way you wanted, it felt like magic.
Two years on, the people I see actually shipping AI features for a living don’t spend most of their time on the prompt. They write code. They think about retrieval, context windows, tool execution, observability, evals, retries, sandboxing. The prompt is part of the work, the same way SQL is part of building a backend. Important. Worth getting right. But a slice of the practice, not the whole thing.
The same task, three layers
At each layer, the unit of work gets larger. At Layer 1, you have a single API call and a string. At Layer 2, that call is wrapped in retrieval and history. At Layer 3, it sits inside a loop that runs tools and decides when to stop.
Layer 1 · Words
Prompt Engineering
The single string the model reads on one call. Roles, instructions, examples, output format. One sequence of tokens.
This is the layer that everyone knows. The whole “prompt” is a list of role-tagged messages. The provider serializes them and the model attends to all of them at once. By default, every request is stateless: there’s no memory between calls. Whatever you want the model to know on a given turn, it has to be in the messages array for that turn.
In LangChain, this is a ChatPromptTemplate piped into a model.
from langchain_anthropic import ChatAnthropicfrom langchain_core.prompts import ChatPromptTemplateprompt = ChatPromptTemplate.from_messages([ ("system", "You are a senior code reviewer. Be terse."), ("user", "Review this PR for race conditions:\n\n{diff}"),])model = ChatAnthropic(model="claude-opus-4-7", max_tokens=1024)chain = prompt | modelresponse = chain.invoke({"diff": diff})print(response.content)
What you control here: the prompt template (system and user messages with placeholder variables), model parameters in the ChatAnthropic constructor (temperature, top_p, max_tokens), and any structured output schema via model.with_structured_output(...). That’s it. Every other layer builds on top of these knobs.
“Prompt engineering” in the 2023 Twitter sense lives entirely inside this layer. A tight system message, a couple of few-shot examples when the task underspecifies, a strict output schema, a reasoning scaffold (CoT, ReAct) where it pays off. Roughly 20% of building anything that ships. The bigger 80% is what we get to next.
Prompts are roughly 20% of the job. The other 80% is software engineering.
Layer 2 · Information
Context Engineering
What the model can see on a single call. The prompt is part of it. Retrieved documents, tool results, summarized history, structured data are the rest. Even a 1M-token window is a finite budget you have to allocate.
Every call you make is implicitly answering one question. Given everything I could put in this window, what should actually go in it? Add too little and the model hallucinates. Add too much and you hit lost-in-the-middle, latency, and cost. Order matters too. Models attend more strongly to what’s near the user turn.
This is the layer where software engineering really shows up. Retrieval pipelines, vector stores, embedding models, hybrid search, re-ranking, summarization, sliding windows, hierarchical memory, dealing with prompt injection inside retrieved content. Each of those is a sub-discipline with its own failure modes. None of them are about wording instructions. If you can build a backend, you can build this.
In LangChain, the work becomes a chain that fills a multi-message template from a retriever and a history compactor.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.runnables import RunnablePassthrough# Context engineering = filling this template, every turnprompt = ChatPromptTemplate.from_messages([ ("system", "{system_prompt}"), MessagesPlaceholder("history"), # summarized prior turns ("system", "Relevant docs:\n{retrieved}"), # RAG output ("system", "Recent tool results:\n{tool_results}"), # freshest first ("user", "{user_turn}"), # anchored last])def format_docs(docs): return "\n\n".join(d.page_content for d in docs)chain = ( RunnablePassthrough.assign( history=lambda x: summarize(x["raw_history"], max_tokens=2000), retrieved=lambda x: format_docs(retriever.invoke(x["user_turn"])), ) | prompt | model.bind_tools(tool_specs))response = chain.invoke({ "system_prompt": SYSTEM, "raw_history": history, "tool_results": recent_tool_results, "user_turn": user_question,})
The retriever is doing real work. Embedding the query, hitting a vector store, optionally re-ranking, returning the top-K chunks that might matter. The summarize step compacts older turns. Get either wrong and the model is answering with the wrong base rate, even though the prompt template and the model haven’t changed.

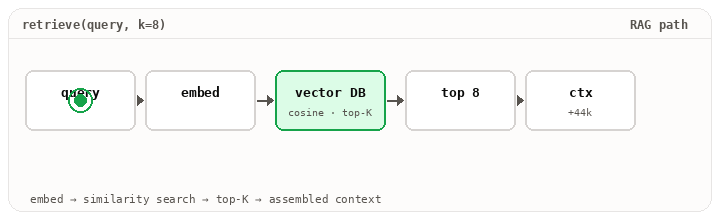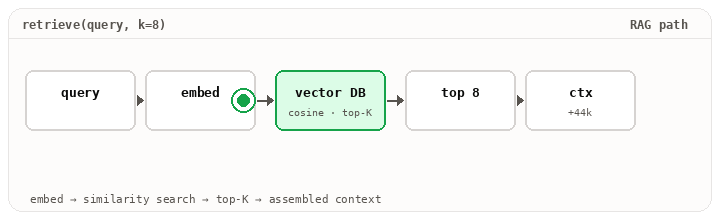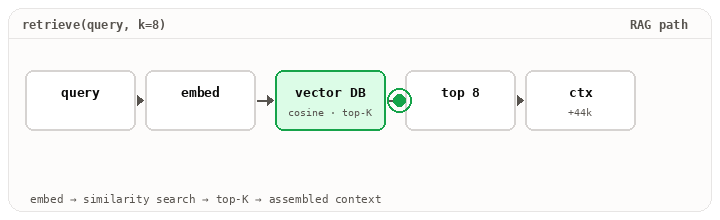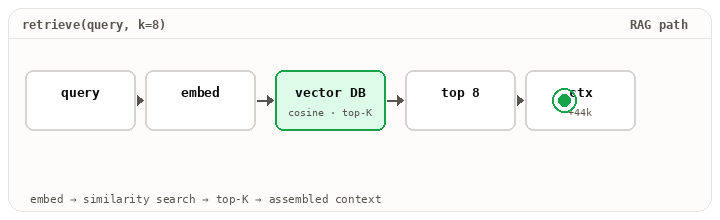
Layer 3 · The runtime
Harness Engineering
The runtime around the call. The agent loop, tool execution, sub-agents, hooks, sandboxing, evals, observability. A model API plus a harness becomes Claude Code, Cursor, Aider, OpenCode.
The harness is, in software terms, a small operating system. It has scheduling (the loop, step budget, retries), I/O (tool calls, MCP servers, external APIs), security (sandboxing, secret scrubbing, permission gates), observability (tracing, replay, eval scores), and error handling (timeouts, fallbacks, graceful degradation). If you’ve designed any production system, every one of those concerns is familiar.
It also turns “one model call” into “a session that does work.” It owns the loop (model to tool to result to model), the step budget, the trace you can replay later, and the hooks that intercept every step. Most production complexity lives here, not in the prompt. MCP is what most modern harnesses speak to wire tools in. In LangChain, bind_tools() exposes the tool-calling protocol. The loop around it is yours to write.
from langchain_anthropic import ChatAnthropicfrom langchain_core.messages import HumanMessage, ToolMessagemodel = ChatAnthropic(model="claude-opus-4-7").bind_tools(tool_specs)messages = [HumanMessage(content=user_request)]tools_by_name = {t.name: t for t in tool_specs}turn = 0while turn < max_turns: resp = model.invoke(messages) messages.append(resp) if not resp.tool_calls: break # plain-text response, done for tc in resp.tool_calls: run_hooks("pre_tool", tc) try: result = sandbox(tools_by_name[tc["name"]]).invoke(tc["args"]) except Exception as e: result = error_payload(e) run_hooks("post_tool", tc, result) messages.append(ToolMessage( content=str(result), tool_call_id=tc["id"], )) turn += 1
Notice what the harness owns that the model doesn’t. The while, the sandbox(...), the run_hooks(...), the budget check, the error recovery. Hooks let you intercept every tool call. Permission prompts, logging, secret scrubbing, cost limits. Sub-agents are this same loop nested with isolated context. (For a higher-level alternative, LangGraph’s create_react_agent wraps this loop into one call. Useful when you want the runtime, less useful when you want to see the runtime.)
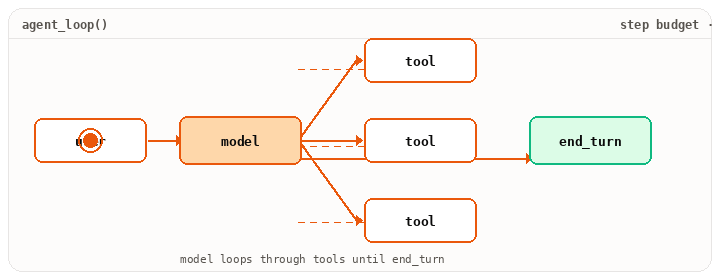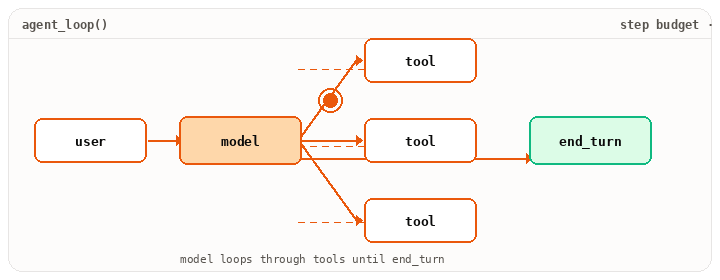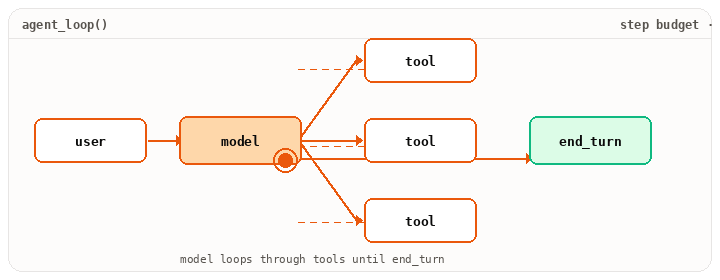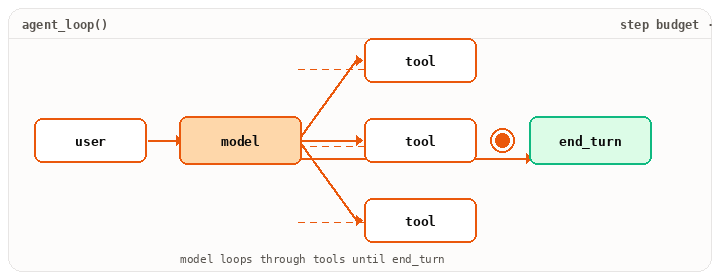
while.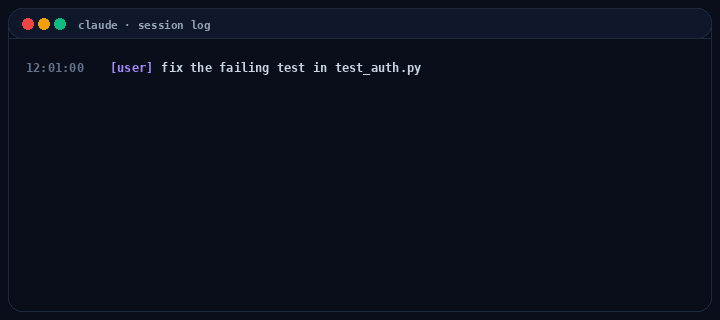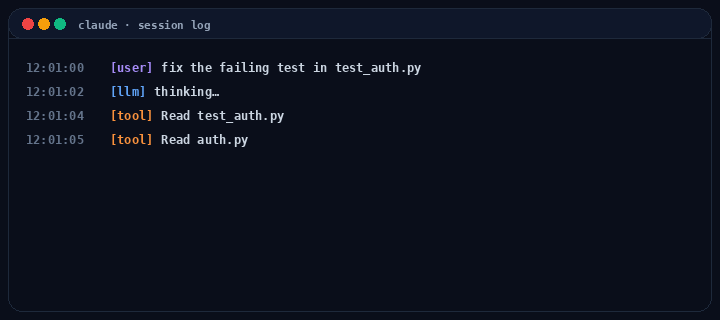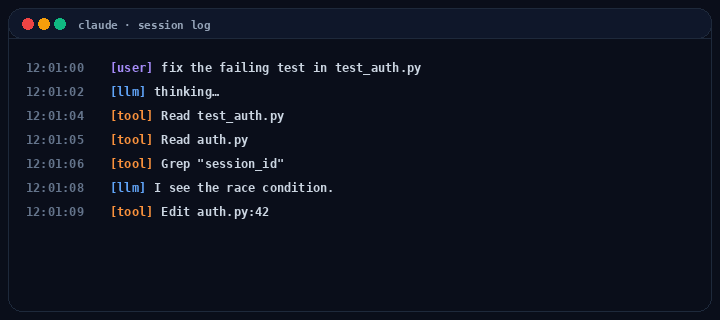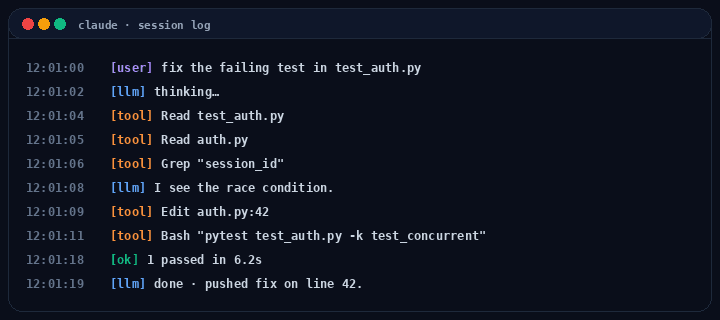
So what?
The reason “prompt engineer” felt like a separate discipline two years ago was that nobody had named the layers yet. We had a single bag labeled “prompt” and threw retrieval, agent loops, tool execution, and instruction wording into it together. Now we have words for the parts. The discipline turns out to be software engineering. The work is software engineering. The model is one of the dependencies. The prompts are short pieces of input data.
If you’ve been writing software for years and feeling vaguely worried that “prompt engineering” is some adjacent skill you missed, you didn’t miss it. You already have most of the muscles. You will spend a few weeks getting fluent at writing system messages and tuning retrieval. The harder skills (how to structure a retry policy, when to compact context, how to design a tool taxonomy, how to reason about end-to-end evals) are the same skills you’ve been using to build production systems. They just have a stochastic component now.
And if you came in through prompt engineering and want to push deeper into agents, the way in is to learn a little more software engineering. Think about retries, idempotency, sandboxes, traces. The discipline is welcoming, and the on-ramp is shorter than it looks.

About the author
Archit Dwivedi builds AI agents and ships them into production. More at /about · what I’m working on · say hi.
Archit · May 2026

Leave a comment