I’ve been running LangChain’s DeepAgents in production for long-horizon tasks, and the same failure mode kept showing up: a job fans out into hundreds or thousands of to-dos, and the moment that whole list lives in one agent’s context, tokens explode, cost climbs, and the model drifts. The agent spends more effort re-reading its own history than doing the work.
So I built deepflow — a small open-source library on top of DeepAgents (not a fork; it only uses the public middleware surface) that keeps the orchestrator’s context tiny while sub-agents do the work, and streams the whole thing live. There are two modes, but one idea behind both: commit to a structure, then stay small while the work runs.
1 · It splits a task into a workflow it builds itself
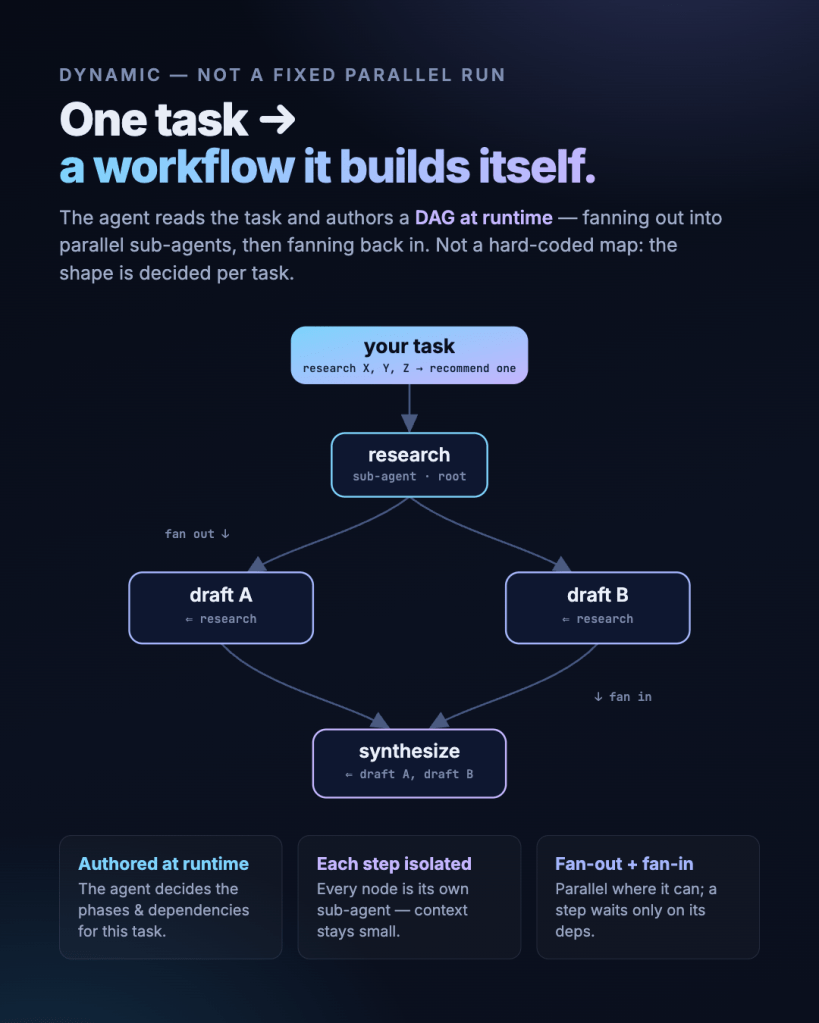
Instead of one agent improvising across an ever-growing conversation, deepflow lets it author a DAG at runtime: fan out into independent sub-agents that run in parallel, then fan back in by consuming each other’s results. The shape of the graph is decided per task — it isn’t a hard-coded pipeline. A research task might fan into three parallel branches and a single synthesis step; a different task gets a different graph.
- Authored at runtime — the agent decides the phases and dependencies for this specific task.
- Each step is isolated — every node is its own sub-agent, so the orchestrator’s context stays small.
- Fan-out + fan-in — steps run in parallel where they can; a step waits only on its declared dependencies.
2 · Write the call, watch it run
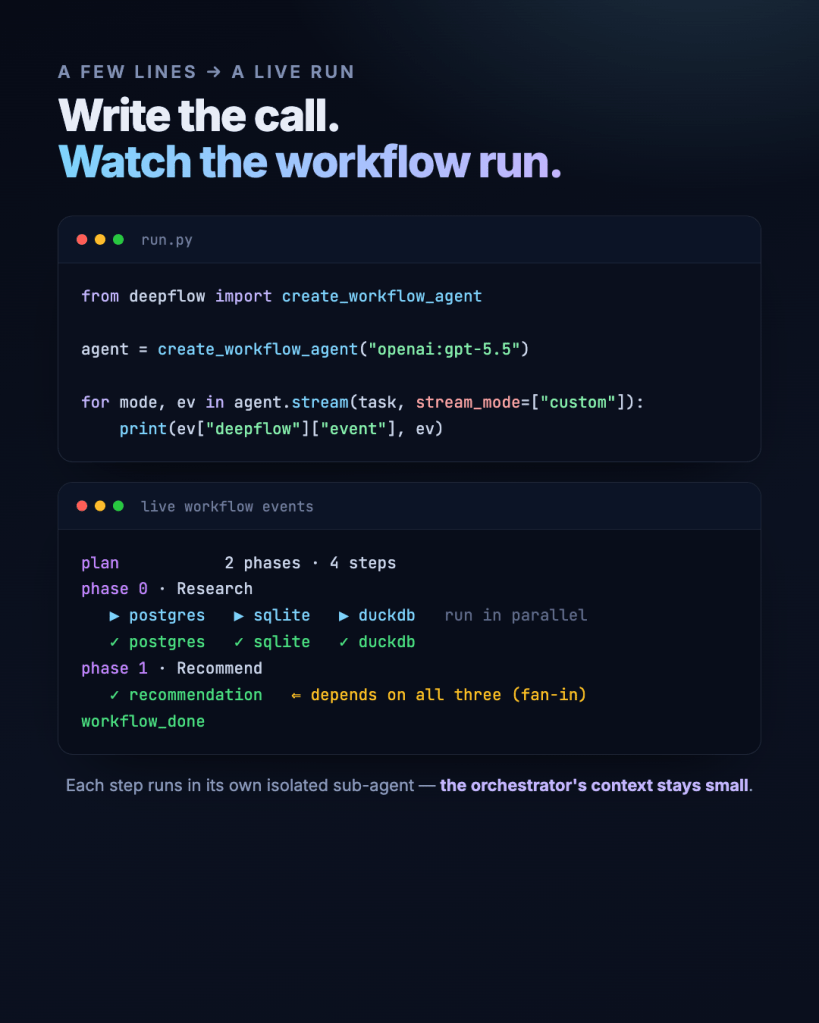
You hand the agent an objective and stream the run live — plan → parallel steps → fan-in → workflow_done. Every phase and step is an event, so it’s never a black box: you can see exactly what fanned out, what each sub-agent did, and when it settled.
from deepflow import create_workflow_agentagent = create_workflow_agent("openai:gpt-5.5")for mode, ev in agent.stream(task, stream_mode=["custom"]): print(ev["deepflow"]["event"], ev)
Because each step runs in its own sub-agent, the orchestrator only ever holds the plan and the step results it actually needs — not the full transcript of everything every worker did.
3 · Hand it a list, and it works through every one
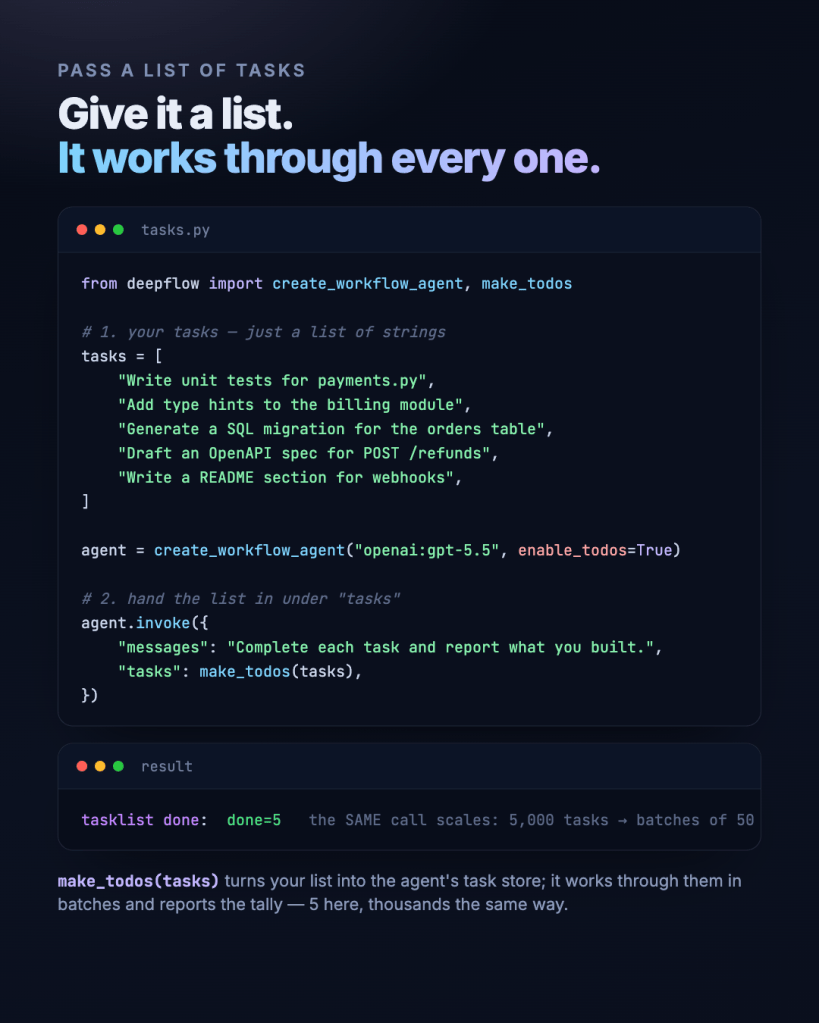
Long-running jobs don’t fan into a tidy graph — they explode into a flat list of hundreds or thousands of tasks. For that, a deepflow workflow drives a task store it never reads in full. Pass a list (or let the agent generate one), and it works through every item:
- Task management — the to-dos live in a store with status; they’re dispatched in disjoint batches, in parallel, with retries for anything that fails.
- Context management — the orchestrator plans from counts, never contents (O(log N) — 10× the tasks adds one digit, not 10× the tokens). Each worker is handed only its slice, and the store lives in state, never in a prompt.
That’s the whole point: the same call that handles 5 tasks handles 5,000 without the orchestrator’s context exploding.
“Done” means verified done
A worker saying done isn’t proof — and the same model that was wrong is a poor judge of its own work. So deepflow has three opt-in layers of verification:
- A deterministic check — attach a shell command to a task (e.g.
pytest -q). After a worker marks it done, the engine runs the check and flips it back to failed if it doesn’t pass. The model can’t fake this. - Evidence — for tasks without a check, workers must write a concrete result (“pytest: 5 passed”), not a restatement of the task.
- A sampled verifier — an independent agent re-checks a fraction of completed tasks and reverts confidently-wrong ones for retry. Sampling keeps it sublinear, so it scales to thousands.
Try it
pip install deepflow-agents — it’s open source, and it’s built on the DeepAgents team’s work at LangChain. Hand your agent a structure, and let it stay small while the work runs itself.

Leave a comment